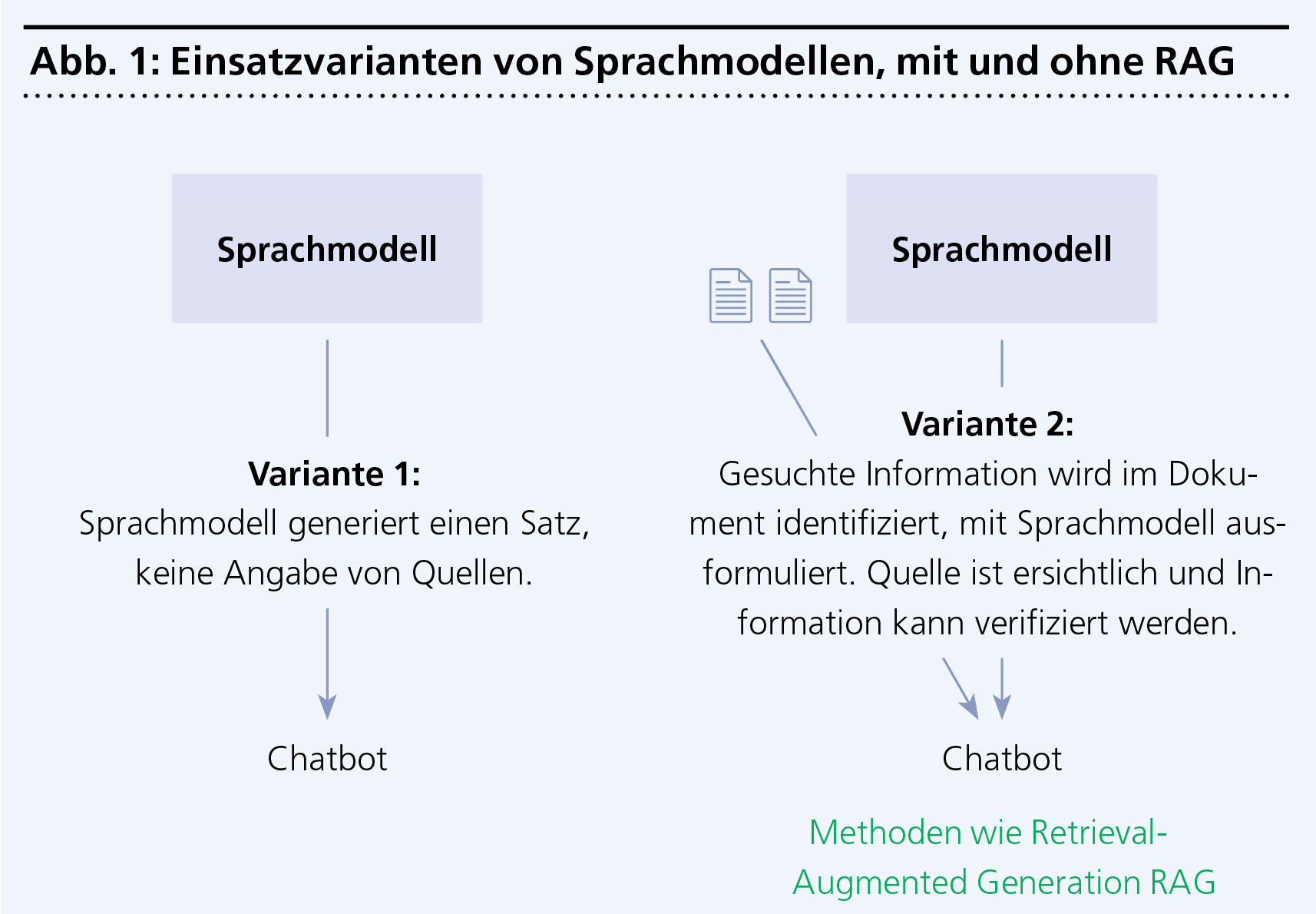
Sprachmodelle können durch Techniken wie Retrieval-Augmented Generation (RAG) mit externem Wissen erweitert werden. Dies ermöglicht genauere und korrektere Antworten, da diesen Modellen reale Daten zugrunde liegen. Das hilft, falsche Ausgaben zu reduzieren, die ein Sprachmodell überzeugend als Fakten präsentiert, sogenannte Halluzinationen, und macht die Ergebnisse zuverlässiger. Insbesondere für kleine und mittlere Unternehmen bietet dies interessante Möglichkeiten, Prozesse zu optimieren oder Kunden einen besseren Service zu bieten.
Die Herausforderungen
Grosse Sprachmodelle (LLMs – englisch für Large Language Models), wie sie in Anwendungen wie ChatGPT verwendet werden, generieren beeindruckende, menschenähnliche Texte. Jedoch weisen sie oft auch Limitationen auf.
Trotz ihrer Leistungsfähigkeit bergen solche Modelle auch Risiken, insbesondere im Hinblick auf die Verlässlichkeit, Nachvollziehbarkeit und Qualität der erzeugten Ausgaben. LLMs prüfen die Inhalte ihrer Antworten nicht und validieren keine Quellen. Daher ist unklar, auf welchen Informationen die generierten Aussagen basieren. Dies erschwert es, die Inhalte zu kontrollieren, und kann insbesondere in professionellen oder regulierten Kontexten problematisch sein. Zudem können unbeabsichtigte Verzerrungen aus den Trainingsdaten in die Texte einfliessen, was zu inhaltlichen Schieflagen oder unangemessenen Formulierungen führen kann. Auch rechtliche Fragen, etwa zum Datenschutz oder zur Nutzung geschützter Inhalte, sind zu berücksichtigen.
Ein grosses Risiko besteht darin, dass die Sprachmodelle manchmal halluzinieren – also mit Überzeugung Dinge behaupten, die nicht wahr sind. Dies geschieht, weil die zugrunde liegenden Modelle darauf trainiert sind, Muster in der Sprache zu erkennen. Basierend auf diesen Mustern generieren sie Texte. Obwohl ihre Ergebnisse oft überzeugend klingen und beeindrucken, verfügen LLMs nicht über ein Verständnis davon, was inhaltlich korrekt ist. Sie überprüfen keine Fakten. Auf Anwendungsebene kann aber eine Faktenprüfung hinzugefügt werden.
Heutzutage werden KI-Tools oft auch mit Web-Suchmaschinen kombiniert, sodass Quellen zu den Texten angegeben werden können. Selbst dann kommt es aber vor, dass bestimmte Inhalte und Themen aus domänenspezifischen Daten nicht abgerufen werden können, beispielsweise, weil es sich um firmeninterne Dokumente handelt.
Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel. Dabei ermöglichen es Entwickler dem Modell, Informationen aus vertrauenswürdigen internen und externen Quellen – wie beispielsweise einer Datenbank oder einer Sammlung von Dokumenten – abzurufen. So lassen sich Fehler reduzieren und die Antworten werden zuverlässiger. Dies insbesondere dann, wenn für die Ausgaben aktuelles oder spezialisiertes Wissen benötigt wird.
Die Lösung
Durch die Kombination eines Sprachmodells mit vertrauenswürdigem domänen-spezifischem Wissen lassen sich die Vorteile beider Ansätze optimal nutzen: die gut formulierten und eloquenten Texte des Sprachmodells und die Zuverlässigkeit kuratierter Informationen. Anstatt vom Modell zu verlangen, alles wissen zu müssen, konzentriert es sich auf seine Stärken: Fragen erfassen, gut formulierte Antworten generieren und sich an den Kontext anpassen.
Die Fakten hingegen bezieht es aus einer echten Datenquelle. Dadurch werden die Antworten nicht nur genauer, sondern auch transparenter. Denn es lässt sich nachvollziehen, woher die Informationen stammen. RAG bietet so eine Möglichkeit, KI-Texte auf solides Wissen zu stützen.
Technisch lässt sich dies auf unterschiedliche Arten umsetzen. In einigen Fällen werden Dokumente wie PDFs, MS-Word-Dateien oder Webseiten in eine durchsuchbare Datenbank geladen, die dann mit dem Sprachmodell verbunden wird.
Die Suche kann mit verschiedenen technischen Methoden implementiert werden, aber die Idee bleibt dieselbe: Wenn jemand eine Frage stellt, sucht das System nach den relevantesten Teilen dieser Dokumente und sendet sie an das Modell, um die Antwort zu verfassen. Mit solchen Methoden wird KI genutzt, um die vorhandenen Daten zu erklären und zu beschreiben. Hingegen werden Daten nicht durch generiertes Wissen ersetzt.
Abbildung 1 zeigt visuell, wie sich eine klassische Anfrage an ein Sprachmodell und eine Architektur mit RAG unterscheidet.